
Pierre is a model-driven software tool that can be used to rapidly craft a search and browse service, which interacts with a data repository. It is used in a two-step process, which begins with a rapid prototyping activity and ends with a production activity. It is also a process that assumes the existence of two key roles: a service designer and a repository designer. A service designer is responsible for crafting the interfaces to services and the repository designer is responsible for managing the data repository and writing code to supply query answers.
In the first phase, the service designer and repository designer agree on an XML schema, which describes the data structures that a repository can publish to the outside world. This schema serves as a sort of contract that allows the designers to do their work relatively independently of one another.
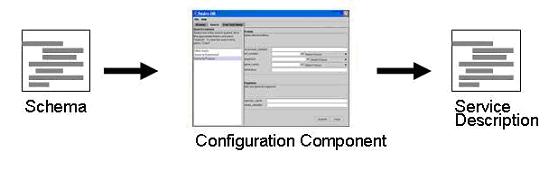
The service designer loads Pierre's configuration tool with the schema and begins the process of developing a specification for a search and browse service. Many feature attributes are expressed in terms of structures that are supplied by the schema. For example, most query features are described in terms of question and answer aspects that are described by schema constructs.
Pierre supports a rapid-prototyping activity that allows end-users to iteratively validate the designers' service specification. The service designers can at any time cause the configuration tool to automatically generate a sample search application that demonstrates the features. The application uses model-generated user interfaces that interact with a dummy data repository, which just returns junk data. This allows users to provide feedback about what kinds of data they would like to query or have returned in a result. The designer can use the tool to associate comments and suggestions with specific features.
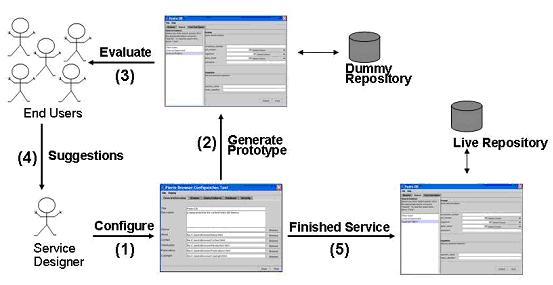
At the end of the first phase, the service designer will have a minimal specification of how a search and browse service should behave. Query feature descriptions will include both formally specified schema fragments and user feedback comments. The service designers can use the configuration tool to create an automatically generated functional specification of the service. The specification can be printed out and used in broader round-table discussions with focus groups.
At a minimum, Pierre can be used to craft a software prototype that is accompanied by a functional specification. Service designers may choose to write their own bespoke search and browse applications or they can continue to use Pierre in a deployment activity.
In the second phase, the repository designer can use a copy of the functional specification to begin writing code that will help support the features requested by the end-users. To create the data repository, they implement a set of methods defined in the "Data Repository" interface. The repository can be implemented using various technologies such as relational or XML-based databases.
The repository designers write the code they need and package their finished product into java JAR files. The service designer can then modify the specification to reference the production repository classes found in those libraries. The service can be tested again in front of end-users but this time it can carry live data.
When the service designer, repository designer and end-users are satisfied with the service prototype, they can move on to creating the finished products. The Pierre configuration tool can be used to simulataneously generate multiple forms of deployment for the same repository. These deployments are whole applications and include the following:
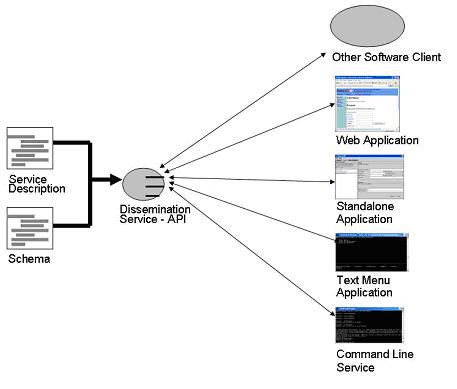
Pierre is intended to allow software developers to focus on writing components for a search and browse service rather than trying to develop a full-scale architecture for an application.
The major benefits are:
Developer activities include:
Much of the code base for Pierre is built using software libraries that were developed for another product called Pedro. Pedro is a model-driven software tool that generates data entry forms given an XML schema. Users use the forms to create data sets that validate against the schema.
There are many aspects of form generation in Pedro that are re-used in Pierre. The way Pierre interprets the data model is exactly the same as the way Pedro interprets one. When you decide to craft a data model, you should look at the data modeller tutorials that appear at http://pedrodownload.man.ac.uk.
Note that you are not required to use the Pedro application for your work. However, this product uses the libraries and as such many of the data modeller tutorial features are the same.