
Service designers develop specifications of search and browse services and then use Pierre to automatically generate multiple service deployments. The activity diagram for a single service is shown below:
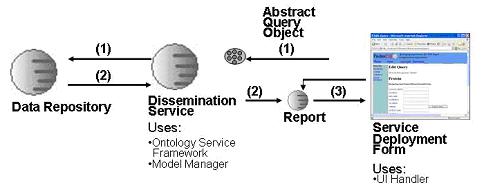
In the scenario of a simple search, the activity begins with an end-user filling in a form. When they press "Submit", the form field values are collected into an abstract query object called a Query Feature (1). The query feature contains a description of the question being asked and the kinds of data expected to be returned in the answer. The dissemination service forwards the query object on to one of the Data Repository's execute(...) methods (1). In the Data Repository implementation of execute(...), the code unpacks the descriptions of the queries and query results and uses this information to help build up a native query. This is then applied to the underlying repository technology (eg. relational or XML-based database). The results are gathered and placed in a Report object.
A report object is responsible for holding and rendering results in various formats. A report is any java class which implements a Report interface. Pierre comes with a number of classes that implement Report and repository designers are expected to create their own customised reports for specialised queries. The report interface can support different layouts such as single page and multiple page display. It can also support various file formats such as XML, HTML, CSV and text. The report also has knowledge of document links, which may implicitly request more information from the repository.
The Data Repository passes the report back to the Dissemination Service(2), which in turn passes it back to the Service Deployment Form. The deployment application then interrogates the report to have it render a display and to advertise its configuration options (3).
A report may have a document link that is a request for more information. In this case, the Deployment form asks the report if it knows about a particular link. If it doesn't, then it is assumed to be a link to some external information page. If it does, then the Deployment Form assumes that this is an implicit request for more information from the data repository. This is then forwarded on in much the same manner as the QueryFeature object was.
The Pierre configuration tool is principally driven off an XML schema, which describes those aspects of a data repository that can be publicly available. This is the domain model and describes the concepts that will be directly interpreted by end-users.
There are some display aspects associated with the concepts that cannot be described using the XML schema language. For example, a context-sensitive help page associated with a particular concept is not something that can be described in the main schema. It is not possible to describe an ontology service that could provide terminology to end-users as they fill out particular form fields.
Pierre uses a configuration file to describe all model aspects, which cannot be described in the schema. It is called "ConfigurationFile.xml" and appears in a model folder.
To learn more about how to craft an XML schema and a configuration file, please look at the online "data modeller" tutorials for Pedro. Pedro is a model-driven application, which renders data entry forms given a particular XML Schema. Users use the forms to create data sets that validate against the schema. Pierre is built on top of Pedro libraries, some of which are responsible for interpreting XML schemas.
Eventually the documentation for data modelling will be packaged independently of the tool. For now, you should know that you craft your model in the same way.
Service designers use Pierre to craft a search and browse service that is customised for a particular domain model. Designers will create definitions of query features, which will be used in Simple and Advanced Search features found in the deployment forms.
A QueryFeature object is a data container object that contains two collections:
The anatomy of a query feature is described below:
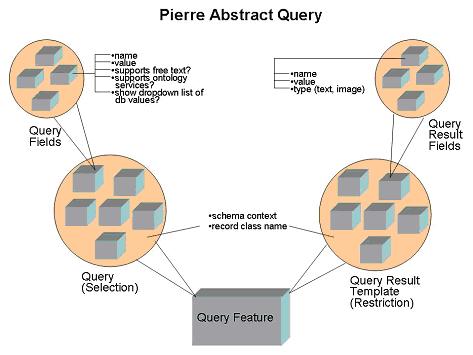
The CannedQuery and QueryResult objects are defined in terms of concepts that come from the XML schema. They will all have a reference to a particular record class name, which corresponds to a record structure in the schema. They will all have a notion of a schema context. This is only important in XML-based implementations of data repositories. A schema context identifies where to find a particular record class in an XML schema. For example, "Organism" could be a record class that is found in the path "Experiment/Organism", "Experiment/Sample/Organism" etc. This path can be used to help construct XPath queries later on.
A CannedQuery comprises one or more QueryField objects. Each of these will have the following characteristics:
The last three characteristics are only used by the various deployment forms. Repository designers need only concern themselves with the "name" and "value" attributes. They can use these values to help build up queries that are written in the language of the repository technology.
A QueryResult comprises the following attributes:
Here, type is only important to the different forms of Pierre applications. Value is something that is only used when in rapid prototyping scenarios. The repository designers only need to know the name of query result fields to help determine what they should return in the results of executing a query.
As you will see in the following sections, a Data Repository object can supply the deployment forms with a security service. This is java class, which implements the interface "SecurityService". The service has a few simple methods that are intended to assess the following things:
Thus far, this aspect of the Pierre system has been stubbed and will be developed at a later date. However, you should be aware that if you write your own implementation of this service, it will have two effects:
As you build up a native query string using information in a query feature, be aware that it may not necessarily have all the fields that are described in the service specification.